A2 LOB-Bench
《LOB-Bench: Benchmarking Generative AI for Finance - an Application to Limit Order Book Data》
ICML Poster LOB-Bench: Benchmarking Generative AI for Finance - an Application to Limit Order Book Data
作者
Peer Nagy-牛津大学:Peer Nagy - Google Scholar
Sascha Frey:Sascha Frey - Google Scholar
1 牛津大学牛津-曼量化金融研究所 2 牛津大学福斯特人工智能研究实验室 3 牛津大学计算机科学系 4 牛津大学统计系 5日论文摩根人工智能研究
问题
序列建模任务
金融数据:其高噪声、厚尾分布以及策略性交互(多智能体交互)
量化评估范式上缺乏共识
背景
限价订单簿——这是股票市场用于跟踪买卖订单以确定任意时刻价格的一种机制
学习了LOBSTER数据集中消息的词元级分布
精确的、低层次的金融系统生成模型:提供反事实分析,来解锁更好的机制设计、稳定性分析或学习算法(例如订单执行)
如何判定生成式人工智能及其他生成式金融模型的真实性与可信度
模型是否重现了文献中已知的高层模式(即"典型化事实")、"影响"或著名的"平方根定律"的定性分析——难以量化,并且可能与真实数据脱节
生成式人工智能,预训练的标准评估仅仅是交叉熵,即模型在留出数据上预测下一词元的准确度——无法捕捉模型在自回归采样(即一次一个词元地生成数据序列)下的表现,因为误差累积可能导致分布偏移
方法
| 评估维度 | 核心指标 / 测试方法 | 目的 |
|---|---|---|
| 分布相似性 | L1距离、Wasserstein-1距离(对极端值敏感) | 衡量生成数据在价差、成交量等静态统计属性上与真实数据的整体和条件分布一致性 |
| 动态行为真实性 | 价格影响响应函数差异(ΔR)、对抗性判别器ROC分数 | 检验模型能否复现市场微观因果关系(如大单冲击)及综合逼真度 |
| 实用价值 | 下游中间价预测任务的F1分数 | 评估生成数据对实际金融任务的附加值 |
| 误差累积分析 | 分布差异随生成步长(t) 的变化曲线 | 量化“自回归陷阱”,即模型在生成长序列时性能衰退的速度 |
实验
数据:Alphabet与Intel股票
基准测试:
生成式自回归状态空间模型、(条件)生成对抗网络以及参数化LOB模型
LOBS5[2309.00638] Generative AI for End-to-End Limit Order Book Modelling: A Token-Level Autoregressive Generative Model of Message Flow Using a Deep State Space Network
补充
1. 核心目标
框架旨在系统化评估生成数据与真实数据分布的相似性,克服传统单步交叉熵评估的局限,尤其是自回归模型中的误差累积问题(“自回归陷阱”),通过度量长序列生成中的分布偏移来量化模型失控。
2. 方法论总览
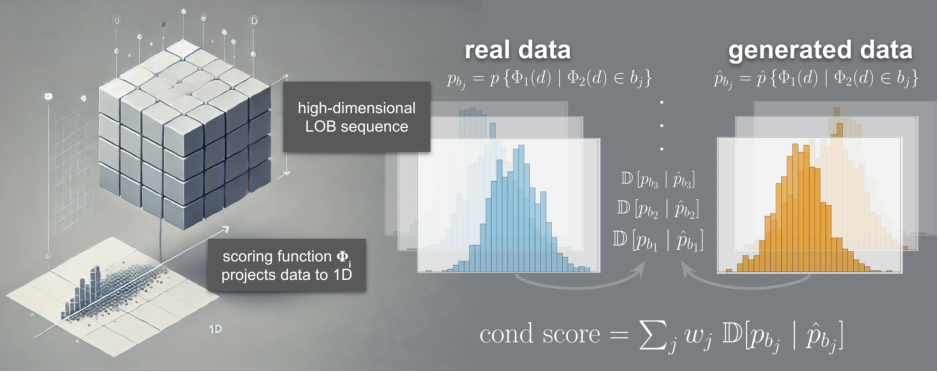
评估的根本在于比较分布。框架通过定义一系列评分函数 (\Phi_i : (\mathcal{M} \times \mathcal{B}) \mapsto \mathbb{R}),将高维序列数据映射至一维标量空间,进而计算其经验分布与真实分布之间的差异。差异度量主要采用 (L_1)范数(总变差距离) 和 Wasserstein-1距离(推土机距离),后者对实际数值距离更为敏感。
3. 三大评估维度
a) 分布相似性评估
-
无条件与条件分布:不仅计算整体分布差异
,还评估条件分布 ,以检验模型在不同市场情境下的适应性。 -
分箱方法:采用Freedman-Diaconis准则进行稳健分箱,以估算分布。
b) 动态行为真实性评估
-
价格影响响应函数:基于Eisler et al. (2012)的方法,计算特定事件 (\pi) 发生后,中间价在滞后时间 (l) 内的平均响应 (R_{\pi}(l))。通过计算生成数据与真实数据响应函数的平均绝对差异 (\Delta R),直接评估模型对市场微观因果关系的复现能力。
-
对抗性测量:训练一个判别器网络作为“最坏情况”评分函数
。其区分真伪的效能(ROC分数)是对生成数据综合真实性的高阶检验。
c) 实用价值评估
- 下游任务性能:通过将生成数据用于训练中间价趋势预测模型(如MLP分类器),并比较其与仅用真实数据训练的模型在留出真实数据上的F1分数,衡量生成数据的外部效用与附加值。
4. 框架创新性与意义
本框架首次为限价订单簿生成模型提供了一个统一、定量、可扩展的分布级评估基准。它将评估重点从单一的“下一词元预测”精度,转向对生成序列整体统计特性、动态因果关系及下游任务实用性的多维综合考量,为模型的比较与改进提供了严谨依据。该方法论亦可扩展至其他高维金融时序数据。
LOB-Bench——一个基于Python实现的基准测试框架
评估以LOBSTER格式生成的逐笔限价订单簿数据的质量与真实感
评估由生成式LOB模型诱导的分布与真实数据之间的相似性
衡量生成数据与真实LOB数据在条件及非条件统计量上的分布差异,支持灵活的多元统计评估
1.引入一组聚合函数Φ,其将高维时间序列LOB数据映射到一组一维子空间。
2.我们计算直方图以估计这些子空间中真实数据和生成数据的分布。
3.使用距离度量(如L1)来比较这些估计分布之间的差异。所选的部分聚合函数深受文献中所用度量的启发。它们也与生成对抗网络直接相关,其中判别器网络等价于给定生成器的"最坏情况"聚合函数。
条件分布评估
首先应用一个聚合函数,然后根据条件变量将这些结果分组到不同的"桶"中。
随后,我们使用前述流程对每个产生的条件分布进行评分
评估在一天中不同时间条件下,买卖价差的分布是否与真实数据中的相应条件分布一致
计算所有条件桶的平均损失,并按每个桶的概率进行加权
基于采样步长进行聚合并与无条件数据进行比较,来评估模型漂移——开环采样中模型失控的一个良好代理指标

基于交叉熵的评估或模型困惑度的计算
评估“自回归陷阱”预测步长区间区间来评估分布的误差散度
即使在下一词元预测任务中出现微小的误差,这些误差也可能在长序列中累积,导致模型偏离训练数据分布。
损失度量
_L_1 范数:值域限制在 [0,1]区间内
Wasserstein-1 距离:评分之间距离敏感
估计条件评分分布之间的差异
解决了一种特定类型的分布偏移:一个评分 Φ1的分布在另一个评分 Φ2 的分布上的变化
-
价差、波动率等评分函数)。
-
无条件评估,L1和Wasserstein
-
条件评估,检查AI在特定市场状态下(如暴涨、暴跌、活跃、清淡)的反应是否合乎真实逻辑。
-
检测自回归陷阱,看AI生成长数据时会不会后期崩盘。
价格影响响应函数
对抗性测量
中间价预测
实验
基准测试还包含常用的LOB统计指标,如买卖价差、订单簿量、订单失衡以及消息到达间隔时间,并辅以经过训练的判别器网络给出的评分
"市场影响指标",即针对数据中特定事件的交叉相关性函数与价格响应函数
生成式自回归状态空间模型、(条件)生成对抗网络以及参数化LOB模型进行了基准测试
我们在五种不同的生成模型上测试了我们的评估框架:四种现代生成式人工智能模型和一种作为基线广泛使用的经典模型。所有模型均在Alphabet Inc (GOOG)和Intel Corporation (INTC)股票数据上进行了测试。我们未呈现Coletta模型在INTC数据上的详细结果,因为该架构仅针对小报价单位股票开发,因此在INTC数据上失效。我们发现了"模型失控"的证据,因为距离分数随着展开步长的增加而增加(图5)。我们还发现,LOBS5模型最能够复现经济学和金融文献中众所周知的标准价格影响曲线。
LOB-Bench如何检验“神似”?
它通过一些高级的、衡量关系的指标来实现,其中最核心的就是价格影响曲线。
-
它问的问题是:“在发生一个‘买入’事件(其规模为X)之后,平均来看,价格会在接下来的1秒、2秒……N秒内如何移动?”
-
“神似”的数据:会展示出一条平滑的、符合金融学理论的曲线(例如,一开始影响快速上升,然后逐渐饱和或缓慢回落)。这表明模型学会了“大单推动价格”这个核心因果关系。
-
“形似”的数据:其价格影响曲线可能是混乱的、扁平的、或者形状怪异的,表明事件和后续价格变化之间没有建立正确的联系。
| 统计量 | 描述 |
|---|---|
| 买卖价差 | 买方愿意支付的最高价格(买价)与卖方愿意接受的最低价格(卖价)之间的差额 |
| 订单簿失衡 | 最优价格的失衡计算为:(买量 - 卖量)/(买量 + 卖量) |
| 消息到达间隔时间 | 连续订单簿事件之间的时间(由于长右尾,采用对数尺度) |
| 撤单时间 | 已撤限价单的提交时间与首次(部分)撤单时间之间的间隔,采用对数尺度测量。 |
| 买/卖量 | LOB买方和卖方所有订单的量。我们也评估仅发生在最优价格水平的量。 |
| 限价单与撤单深度 | 新限价单或撤单价格与中间价的绝对距离 |
| 限价单与撤单层级 | 事件发生的价格水平(∈ 自然数) |
| 每分钟成交量 | 以一秒钟为间隔的成交额,缩放至一分钟。 |
| 订单流失衡 | 来自Cont等人(2012)的度量,考虑滚动消息窗口内提交订单的失衡。 |
| OFI(涨/平/跌) | 上述OFI,根据后续消息的中间价变动方向(上涨/不变/下跌)进行条件化。 |
结论
-
一种新颖的用于分布评估的LOB基准测试:首个专注于对模型性能进行完整分布量化的LOB基准测试。这解决了先前工作依赖对典型化事实进行定性比较的局限性,使得严格的模型比较难以进行并阻碍了研究进展。
-
用于针对性改进的可解释评分函数:使用直观的评分函数能够实现针对性的模型开发与改进。
-
判别器评分的挑战性:即使大多数其他统计量高度吻合,基于判别器的评分为未来的生成模型设定了高门槛。
-
识别常见故障模式:作为分布误差随展开步长函数计算出的发散度量,突显了一个普遍存在的故障模式以指导研究。
-
易用性与可访问性:开源、易于应用的基准测试,仅需要LOBSTER格式的数据。
-
可扩展至其他评分函数。
-
可迁移至其他领域:该理论框架可适用于LOB数据之外的其他高维生成式时间序列任务。
规律
| 项目 | 内容 |
|---|---|
| 论文标题 | LOB-Bench: Benchmarking Generative AI for Finance – an Application to Limit Order Book Data |
| 研究背景 | 高频 LOB 数据噪声大、重尾、多智能体交互;缺乏标准化评价体系;现有研究多依赖“定性”对比。 |
| 核心贡献 | ① 第一套系统的 LOB 生成模型分布式 Benchmark; ② 包含分布、条件分布、多指标、市场冲击函数等评价; ③ 支持多类生成模型(GAN/S5/RWKV/经典模型); ④ 开源可扩展。 |
| 数据与特征 | LOBSTER(GOOG、INTC),消息级别订单与订单簿状态(价格、数量、方向、inter-arrival time)。 |
| 方法技术路线 | - 统计分布:L1、Wasserstein-1; - 条件分布:按时间/价差等分桶; - 市场冲击:六类事件类型响应函数; - 对抗评分(训练 discriminator)评估可区分度; - 下游任务:mid-price movement prediction。 |
| 实验结果 | S5 模型整体表现最佳; RWKV 与 GAN 有明显偏离; 传统模型表现最差; 对抗鉴别器能轻松区分假数据(ROC≈0.83 表示仍有大量可改进空间)。 |
| 关键启示 | 单纯“next-token”训练不足以保证长序列生成质量; 需要综合分布指标; LOB 生成模型仍远未达到难以鉴别的水平。 |
| 局限性 | 不评估交易收益; 模型在长序列存在“derailment”; 指标更多是统计而非经济意义。 |
| 未来方向 | 向多资产、跨市场扩展; 结合 RL 生成交易轨迹; 结合因果性与微观结构理论; 加入策略模拟模块。 |